
(责任编辑:娱乐)
Stable Diffusion ControlNet Inpainting Workflow:AI图像修复与编辑的终极指南
 在AI图像生成领域,Stable Diffusion ControlNet Inpainting Workflow已成为专业创作者不可或缺的工具。它结合了Stable Diffusion的强大生成能力
...[详细]
在AI图像生成领域,Stable Diffusion ControlNet Inpainting Workflow已成为专业创作者不可或缺的工具。它结合了Stable Diffusion的强大生成能力
...[详细]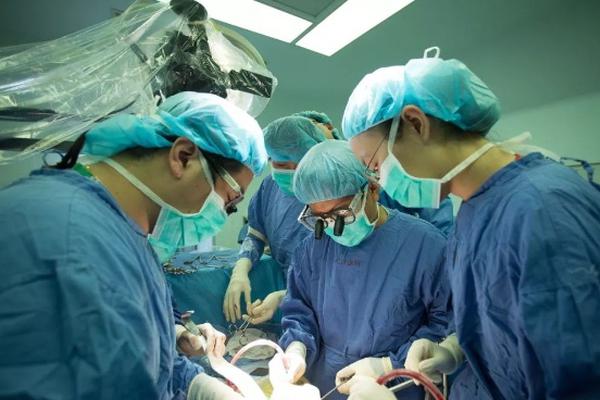 近日,可口可乐公司正式在全球市场推出全新含益生菌的碳酸饮料系列,这一突破性产品将碳酸饮料的畅爽口感与益生菌的健康益处相结合,引发行业广泛关注。作为一款融合传统与创新的智能饮品,该系列旨在满足消费者对功
...[详细]
近日,可口可乐公司正式在全球市场推出全新含益生菌的碳酸饮料系列,这一突破性产品将碳酸饮料的畅爽口感与益生菌的健康益处相结合,引发行业广泛关注。作为一款融合传统与创新的智能饮品,该系列旨在满足消费者对功
...[详细] 近日,今年第11号台风“摩羯”在海南省文昌市沿海登陆,中心附近最大风力达到17级以上,成为近年来登陆我国的最强台风之一。受其影响,海南、广东、广西等地出现强风暴雨,部分城市内涝严重,树木倒伏,电力中断
...[详细]
近日,今年第11号台风“摩羯”在海南省文昌市沿海登陆,中心附近最大风力达到17级以上,成为近年来登陆我国的最强台风之一。受其影响,海南、广东、广西等地出现强风暴雨,部分城市内涝严重,树木倒伏,电力中断
...[详细]Google Trends 新闻选题实时热点跟踪:智能工具助力内容创作
 在信息爆炸的时代,新闻编辑和内容创作者需要快速捕捉公众关注焦点,而 Google Trends 新闻选题实时热点跟踪工具正是为此而生。这款智能平台通过分析全球搜索数据,帮助用户精准定位热门话题、预测趋
...[详细]
在信息爆炸的时代,新闻编辑和内容创作者需要快速捕捉公众关注焦点,而 Google Trends 新闻选题实时热点跟踪工具正是为此而生。这款智能平台通过分析全球搜索数据,帮助用户精准定位热门话题、预测趋
...[详细] 近期,英伟达下一代旗舰显卡 RTX 5090 的详细规格在多个渠道曝光,引发业界广泛关注。据泄露信息显示,基于全新 Blackwell 架构的 RTX 5090 在核心数量、显存带宽及 AI 算力上均
...[详细]
近期,英伟达下一代旗舰显卡 RTX 5090 的详细规格在多个渠道曝光,引发业界广泛关注。据泄露信息显示,基于全新 Blackwell 架构的 RTX 5090 在核心数量、显存带宽及 AI 算力上均
...[详细]LexisNexis News Database Search:专业新闻检索的智能中枢
 在信息爆炸的时代,快速、精准地获取高质量新闻内容已成为专业人士的核心竞争力。LexisNexis News Database Search 作为全球领先的新闻与法律信息服务平台,凭借其深度索引与智能分
...[详细]
在信息爆炸的时代,快速、精准地获取高质量新闻内容已成为专业人士的核心竞争力。LexisNexis News Database Search 作为全球领先的新闻与法律信息服务平台,凭借其深度索引与智能分
...[详细]全球首款器官3D打印心脏移植手术在瑞典完成:突破性智能工具引领医疗革命
 近日,瑞典卡罗林斯卡医学院成功完成了全球首例采用3D生物打印技术进行的心脏移植手术,为终末期心脏病患者带来了全新希望。这项里程碑式的手术背后,是一套由瑞典公司Cellink与多家研究机构联合开发的智能
...[详细]
近日,瑞典卡罗林斯卡医学院成功完成了全球首例采用3D生物打印技术进行的心脏移植手术,为终末期心脏病患者带来了全新希望。这项里程碑式的手术背后,是一套由瑞典公司Cellink与多家研究机构联合开发的智能
...[详细] 根据国家统计局最新数据,2024年中国出生人口进一步下降,人口负增长趋势加剧,预计全年出生人口不足900万,较2023年减少约100万。专家指出,育龄妇女减少、生育意愿低迷是主因。人口结构变化将深刻影
...[详细]
根据国家统计局最新数据,2024年中国出生人口进一步下降,人口负增长趋势加剧,预计全年出生人口不足900万,较2023年减少约100万。专家指出,育龄妇女减少、生育意愿低迷是主因。人口结构变化将深刻影
...[详细]日产Ariya e-4ORCE雪地模式:智能扭矩分配如何征服冰雪路面
 近日,日产Ariya e-4ORCE在北方极寒测试场完成新一轮冰雪路况挑战,其专属雪地模式下的扭矩分配技术再度引发行业关注。作为日产纯电旗舰SUV,Ariya搭载的e-4ORCE双电机四驱系统能够实时
...[详细]
近日,日产Ariya e-4ORCE在北方极寒测试场完成新一轮冰雪路况挑战,其专属雪地模式下的扭矩分配技术再度引发行业关注。作为日产纯电旗舰SUV,Ariya搭载的e-4ORCE双电机四驱系统能够实时
...[详细]黄金价格突破2400美元/盎司,央行持续增持——智能分析工具助您把握投资先机
 近期,国际金价强势突破每盎司2400美元大关,同时中国人民银行连续多月增持黄金储备,引发市场广泛关注。在此背景下,一款名为「金智宝」的智能黄金分析工具应运而生,帮助投资者实时追踪金价动态、解读央行政策
...[详细]
近期,国际金价强势突破每盎司2400美元大关,同时中国人民银行连续多月增持黄金储备,引发市场广泛关注。在此背景下,一款名为「金智宝」的智能黄金分析工具应运而生,帮助投资者实时追踪金价动态、解读央行政策
...[详细] 特斯拉FSD V12无城市限制驾驶实测:全面解析智能驾驶新纪元
特斯拉FSD V12无城市限制驾驶实测:全面解析智能驾驶新纪元 国际油价突破每桶120美元 欧佩克+宣布增产计划
国际油价突破每桶120美元 欧佩克+宣布增产计划 比亚迪锂矿资源勘探新发现:智利项目取得重大突破
比亚迪锂矿资源勘探新发现:智利项目取得重大突破 Alertbot for News: Setting Up Real-Time News Alerts – 智能新闻提醒工具全面解析
Alertbot for News: Setting Up Real-Time News Alerts – 智能新闻提醒工具全面解析 任天堂Switch 2游戏性能对比全面分析:官方工具助力玩家选择
任天堂Switch 2游戏性能对比全面分析:官方工具助力玩家选择
